Given an unlabeled offline dataset, we learn a generalized occupancy model that models both
``what outcomes can happen?" and ``how to achieve a particular outcome?" This is used for quick
adaptation to new downstream tasks without re-planning or test-time policy optimization.
Abstract
Intelligent agents must be generalists - showing the ability to quickly adapt and generalize to
varying tasks. Within the framework of reinforcement learning (RL), model-based RL algorithms learn a
task-agnostic dynamics model of the world, in principle allowing them to generalize to arbitrary rewards. However,
one-step models naturally suffer from compounding errors, making them ineffective for problems with long
horizons and large state spaces. In this work, we propose a novel class of models - generalized occupancy models
(GOMs) - that retain the generality of model-based RL while avoiding compounding error. The key idea behind
GOMs is to model the distribution of all possible long-term outcomes from a given state under the coverage of a
stationary dataset, along with a policy that realizes a particular outcome from the given state. These models can
then quickly be used to select the optimal action for arbitrary new tasks, without having to redo policy
optimization. By directly modeling long-term outcomes, GOMs avoid compounding error while retaining generality
across arbitrary reward functions. We provide a practical instantiation of GOMs using diffusion models and show
its efficacy as a new class of transferable models, both theoretically and empirically across a variety of simulated
robotics problems.
Method
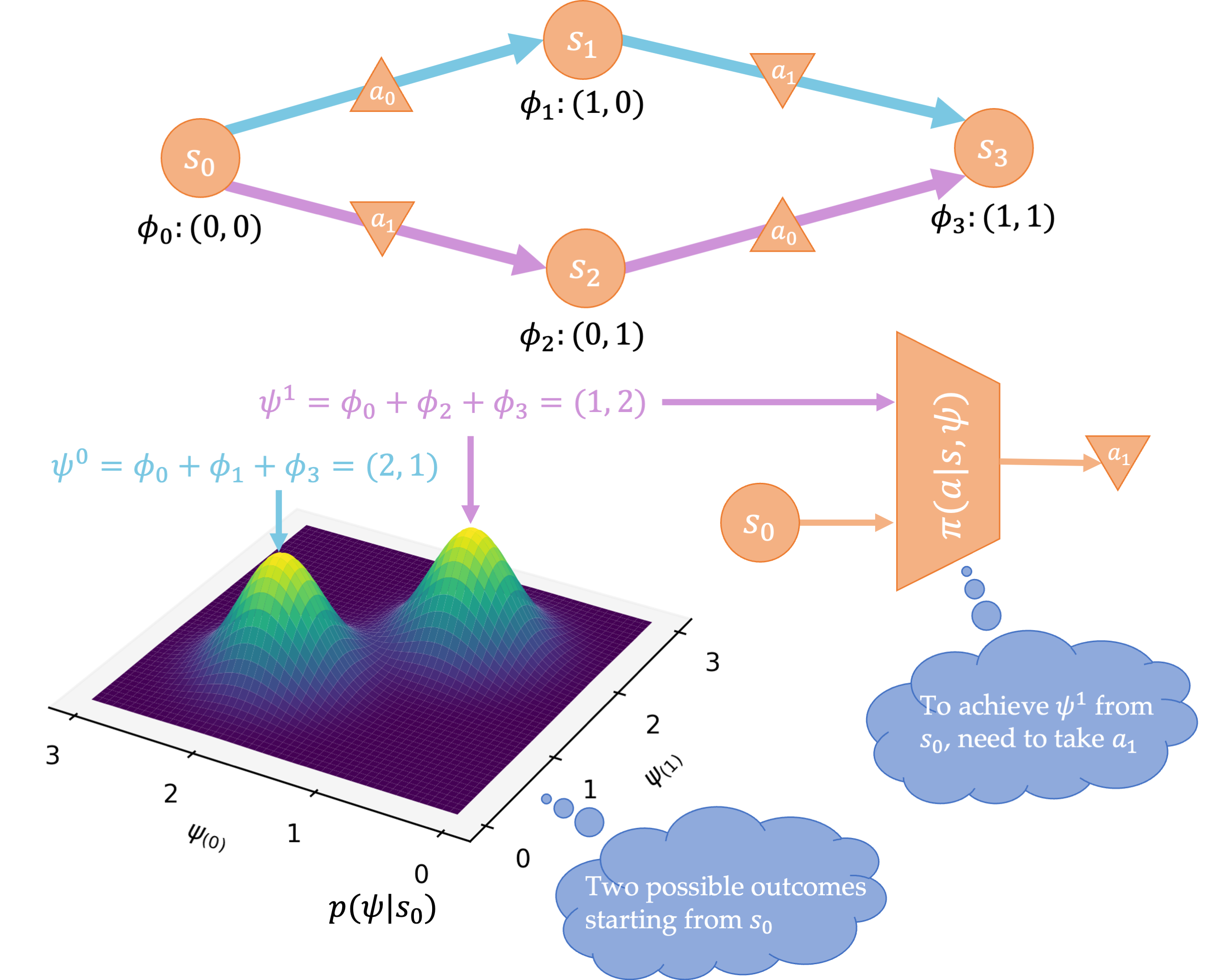
Learning Generalized Occupancy Models
GOMs learn:
Distribution of all possible outcomes, represented by discounted sums of state-dependent cumulants along trajectories.
A readout policy that produces an action to realize a particular outcome.
Modeling the discounted sum of cumulants makes GOMs reward-agnostic, while
modeling the distribution of all possible outcomes makes them policy-agnostic. These allow
GOMs to retain the generality of model-based RL while avoiding compounding error.
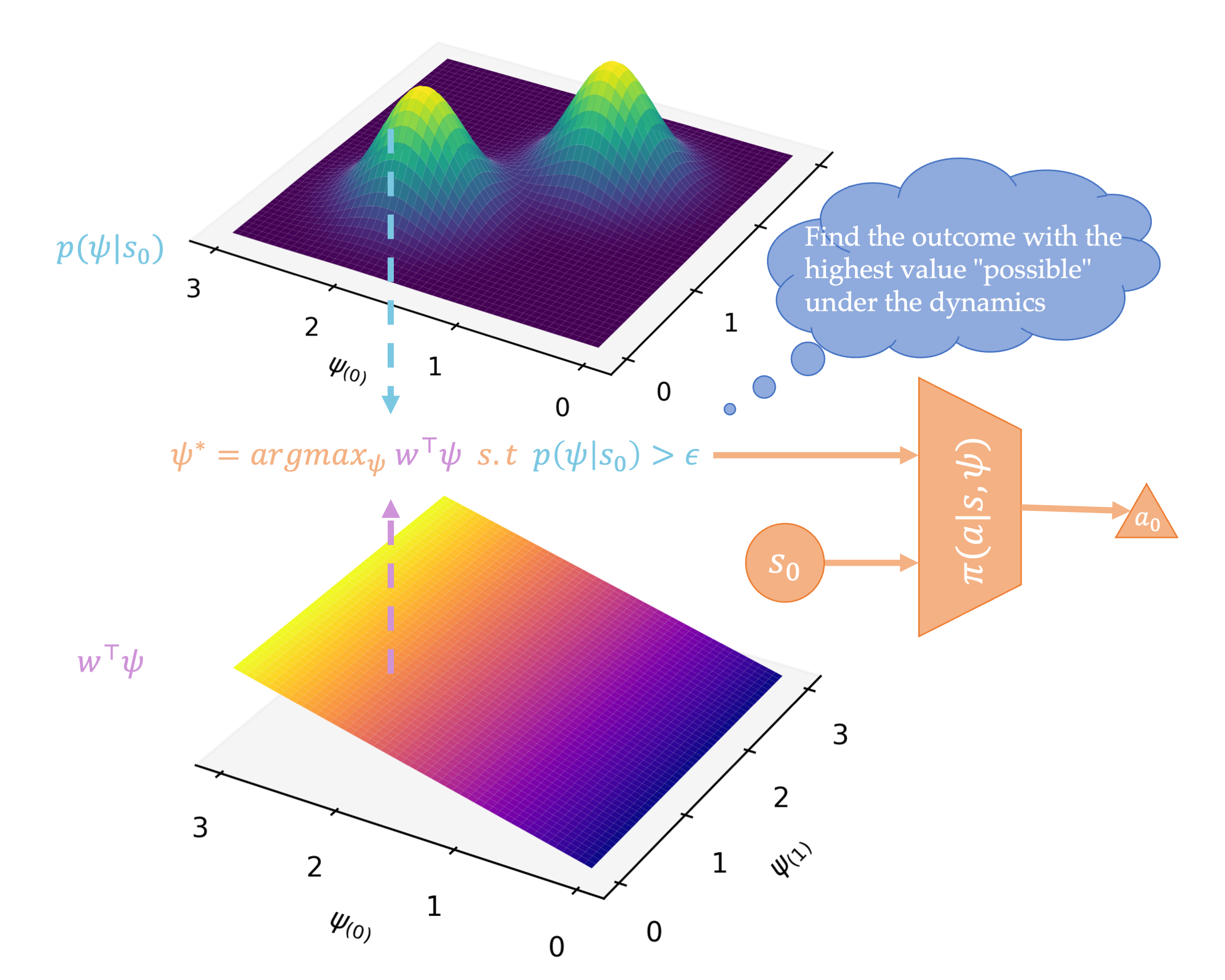
Adaptation and planning via GOMs
Assuming a linear dependence of rewards on cumulants, transferring to downstream tasks reduces to performing
linear regression and solving a simple optimization problem for the optimal possible outcome. This is fed
into the readout policy to produce an action.
Experiments
Multitask Transfer
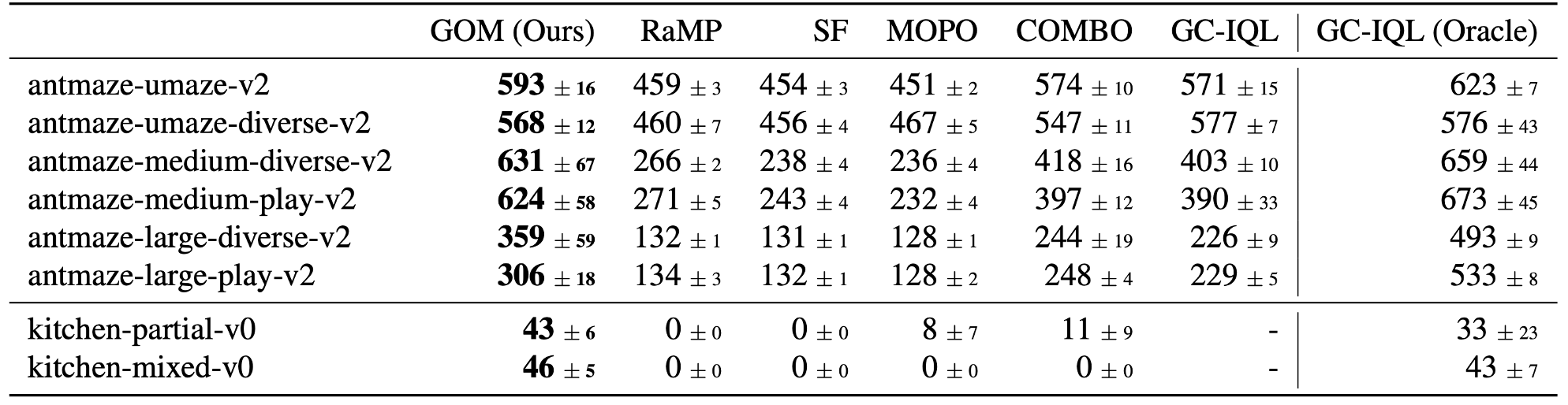
We evaluate GOMs' ability to transfer to challenging downstream tasks on the D4RL benchmark.
GOMs show superior performance transferring to the hardest tasks compared to model-based RL, successor
features, and mispecified goal-conditioned baselines, while being competitive with an oracle using
previldged information.
To demonstrate GOM's broad transferability, we plot the normalized
returns for reaching various goals in antmaze, where each tile corresponds to the task of
navigating the robot to reach that particular tile. GOMs successfully transfer across a
majority of tasks, whereas model-based RL struggles on longer-horizon tasks.
Transferring to Arbitrary Rewards
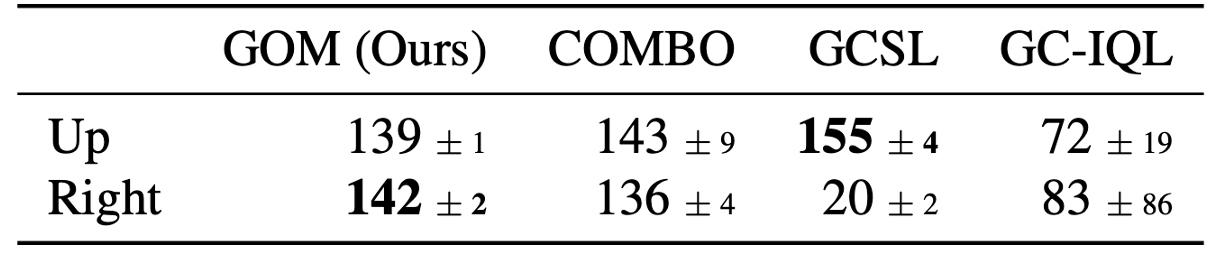
We show that GOMs can adapt to aribitrary rewards beyond goal-reaching in an antmaze
preference environment, where the agent has to take a pariticular path to reach the goal
according to human preference (specified as reward functions). GOMs and model-based RL
are able to complete the task according to the human preference, whereas goal-conditioned
RL baselines do not conform to perferences.
We further demonstrate GOMs' arbitrary transfer capability by training an agent to
track various trajectories as denoted by the colored cells. All these runs share the
same outcome model and policy, only differing in the reward regression weights.
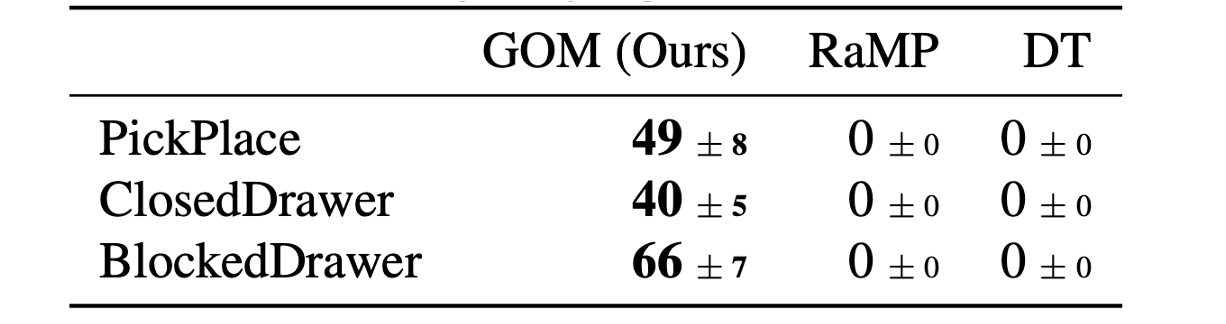
Trajectory Stitching
Since GOMs are trained with distributional Bellman backup, they are able to perform "trajectory stitching,"
i.e. recovering optimal trajectories by combining suboptimal trajectories. We validate GOMs' stitching
capability on the roboverse benchmark, where each task consists of two subtasks, but the dataset
only contains trajectories for each individual subtask. GOMs can complete the tasks by stitching
subtrajectories, whereas monte-carlo-based baselines cannot.
BibTeX
@article{zhu2024gom,
author = {Zhu, Chuning and Wang, Xinqi and Han, Tyler and Du, Simon Shaolei and Gupta, Abhishek},
title = {Transferable Reinforcement Learning via Generalized Occupancy Models},
booktitle = {ArXiv Preprint},
year = {2024},
}