Interactive demo by Joshua Tran
OmniReset overcomes the exploration bottleneck by automatically generating diverse reset distributions and scaling up RL training. No demos, no reward shaping, just RL. The resulting policies are distilled to RGB and transferred to the real world zero-shot.
Automatically generate diverse reset states for PPO.
Scale PPO to 64K+ environments.
Distill to RGB with extensive visual randomizations.
Zero-shot sim2real transfer from RGB.
Robustness and Emergent Retrying Behavior
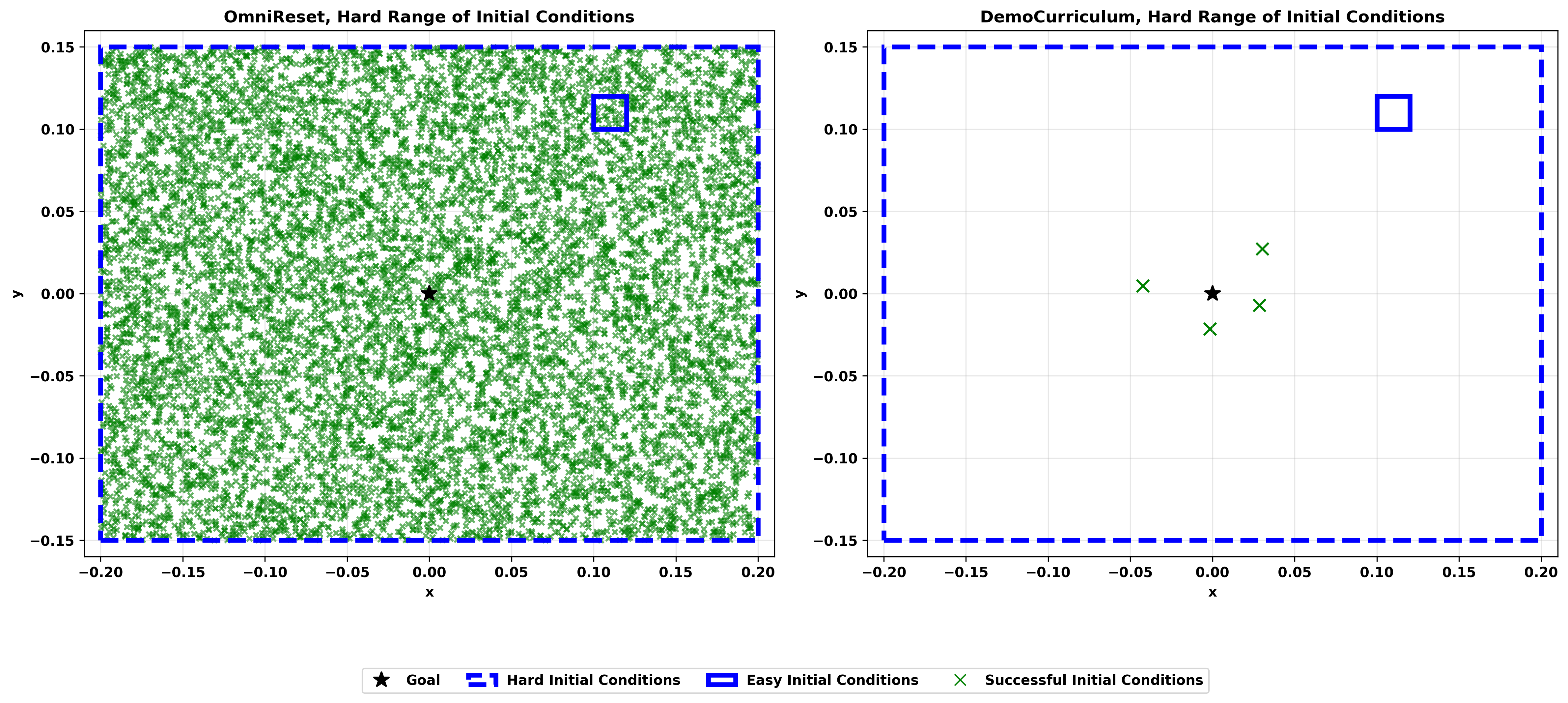
OmniReset policies are robust to perturbations and succeed across the entire workspace. OmniReset learns robust policies over ranges of initial conditions >300x wider than baselines (see comparisons below).
Robustness to perturbations
Difficult initial conditions at the edges of the workspace
Non-Prehensile Behaviors
OmniReset discovers non-prehensile skills that exploit environment dynamics. Watch the robot reorient the peg using the hole!
Diverse Long-Horizon Stitching
OmniReset stitches together diverse, emergent skills into long-horizon behaviors, with no task-specific priors.
avoid obstacle → flip → push → wiggle in
reach → flip → insert
reach → pick → insert → release → twist
OmniReset aims to cover all contact-rich states the robot might encounter and all potential paths to the goal. Large-scale RL (64K+ environments) then sorts through these options to find successful behaviors for each task.
The user only specifies the pose of the object at success. From that, we automatically generate the following distributions to cover all reasonable robot-object configurations.
Near Goal
The object near the goal with the gripper close to the object.
Grasped
The robot gripper grasping the object.
Near Object
The robot gripper close to the object.
Reaching
The robot gripper randomly positioned.
Our reset distributions zoomed in on leg to show diversity of object-robot configurations.
Near Goal
Grasped
OmniReset requires no curricula or reward shaping, just diverse resets and large-scale compute. PPO naturally learns backwards from near-goal states to the full workspace.
OmniReset scales gracefully to a large number of tasks.
Leg Twisting
Screw the leg into the table.
Drawer Assembly
Insert the drawer into the drawer box.
Peg Insertion
Insert the peg in the hole.
Rectangle on Wall
Reorient the rectangular block to the target position on the wall.
Cube Stacking
Stack the cubes on top of each other.
Birthday Party
Pick up the cupcake and place it on the plate.
Leg Twisting (×4)
Demo only. Runs the leg twisting policy four times from a fixed initial state (no large distribution coverage).
OmniReset policies distilled to RGB with zero-shot sim2real transfer.
We evaluate on easy (restricted initial conditions) and hard (full workspace) variants of each task. Baselines rarely succeed on hard settings. The scatter plot shows successful initial conditions for OmniReset (left) vs. the strongest baseline, Demo Curriculum (right).
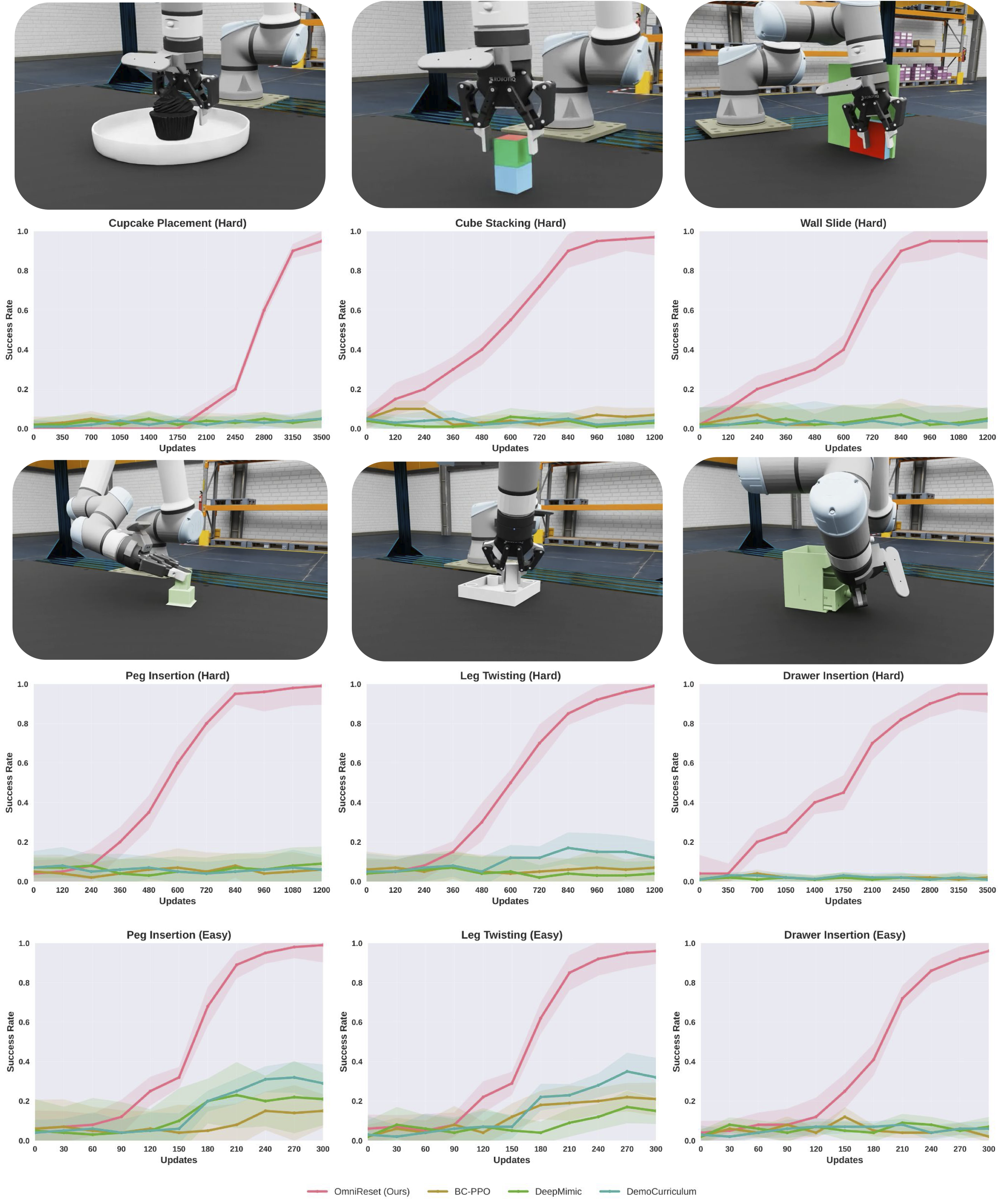
Here we plot learning curves for different methods across different variations of the task. OmniReset consistently achieves high success rates where baselines struggle to make progress in learning.
The three stacked views on the right are policy inputs; the main view is for visualization only.
The most impressive moments from our evaluations, supercut.
Peg insertion
Table assembly
Drawer assembly
Policies recover from perturbations and retry after mistakes.
Peg Insertion
Table Assembly
Policies succeed under randomized target positions.
Peg Insertion
Table Assembly
Policy failures supercut from evaluations.
Peg insertion
Table assembly
Drawer assembly
Full, uncut, continuous evaluations.
Peg insertion
Table assembly
Drawer assembly
@inproceedings{yin2026emergent,
title={Emergent Dexterity via Diverse Resets and Large-Scale Reinforcement Learning},
author={Patrick Yin and Tyler Westenbroek and Zhengyu Zhang and Joshua Tran and Ignacio Dagnino and Eeshani Shilamkar and Numfor Mbiziwo-Tiapo and Simran Bagaria and Xinlei Liu and Galen Mullins and Andrey Kolobov and Abhishek Gupta},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://arxiv.org/abs/2603.15789},
}